
In the rapidly evolving landscape of artificial intelligence, Agentic AI represents a paradigm shift. Moving beyond simple chatbots and generative models, these autonomous systems are designed to complete complex tasks, interact with diverse tools, and make decisions with minimal human oversight. This promise of an autonomous digital workforce is compelling, offering unprecedented efficiencies and innovation. However, beneath the surface of this transformative technology lies a significant, often underestimated challenge: the hidden and escalating costs associated with token consumption.
Many organizations, eager to harness the power of Agentic AI, are encountering an unwelcome surprise: a phenomenon we at JetX Media term "token bill shock." This occurs when the operational expenses of AI agents far exceed initial projections, primarily due to the intricate and often opaque economics of Large Language Model (LLM) token usage. As AI agents become more sophisticated and their interactions more complex, understanding and managing these costs is no longer a secondary concern but a critical imperative for sustainable AI adoption.
At JetX Media, we specialize in optimizing AI workflows and building robust agentic systems that deliver tangible business value without unexpected financial burdens. If your organization is exploring or already deploying Agentic AI, understanding the nuances of token economics and implementing proactive cost-control strategies is essential. This comprehensive guide will delve into why AI agents can be surprisingly expensive, expose common pitfalls, and provide advanced strategies to prevent token bill shock, ensuring your AI investments yield maximum return.
01 Understanding the Currency of AI: What Are Tokens and Why Do They Cost So Much?
To grasp the hidden costs of Agentic AI, one must first understand the fundamental unit of transaction: the token. In the context of LLMs, a token can be a word, a part of a word, or even a punctuation mark. When you interact with an LLM, both your input (prompt) and the model's output (response) are broken down into tokens. The cost of using an LLM is directly tied to the number of tokens processed, often priced per thousand tokens, with different rates for input and output.
For simple generative AI tasks, token costs are relatively straightforward. However, Agentic AI introduces a layer of complexity. An AI agent doesn't just process a single prompt; it engages in a multi-step reasoning process, often involving:
- **Planning**: Breaking down a complex goal into smaller sub-tasks.
- **Tool Use**: Interacting with external APIs, databases, or web services, each interaction requiring new prompts and responses.
- **Observation**: Processing the results of tool actions, which then become new input tokens.
- **Reflection**: Evaluating progress, identifying errors, and refining its plan, generating internal "thinking traces" that also consume tokens.
- **Memory Management**: Storing and retrieving past interactions, which can add to the context window and thus token count.
This iterative "sense-think-act" loop means that a single high-level instruction to an AI agent can translate into hundreds, if not thousands, of individual token transactions. As Barak Turovsky, Operating Advisor at Bessemer Venture Partners, aptly puts it, "The core risk isn’t vulnerability, it’s *unbounded capability*." This unbounded capability, while powerful, can lead to unbounded token consumption if not properly managed.
02 Common Pitfalls: Where AI Agents Bleed Your Budget Dry
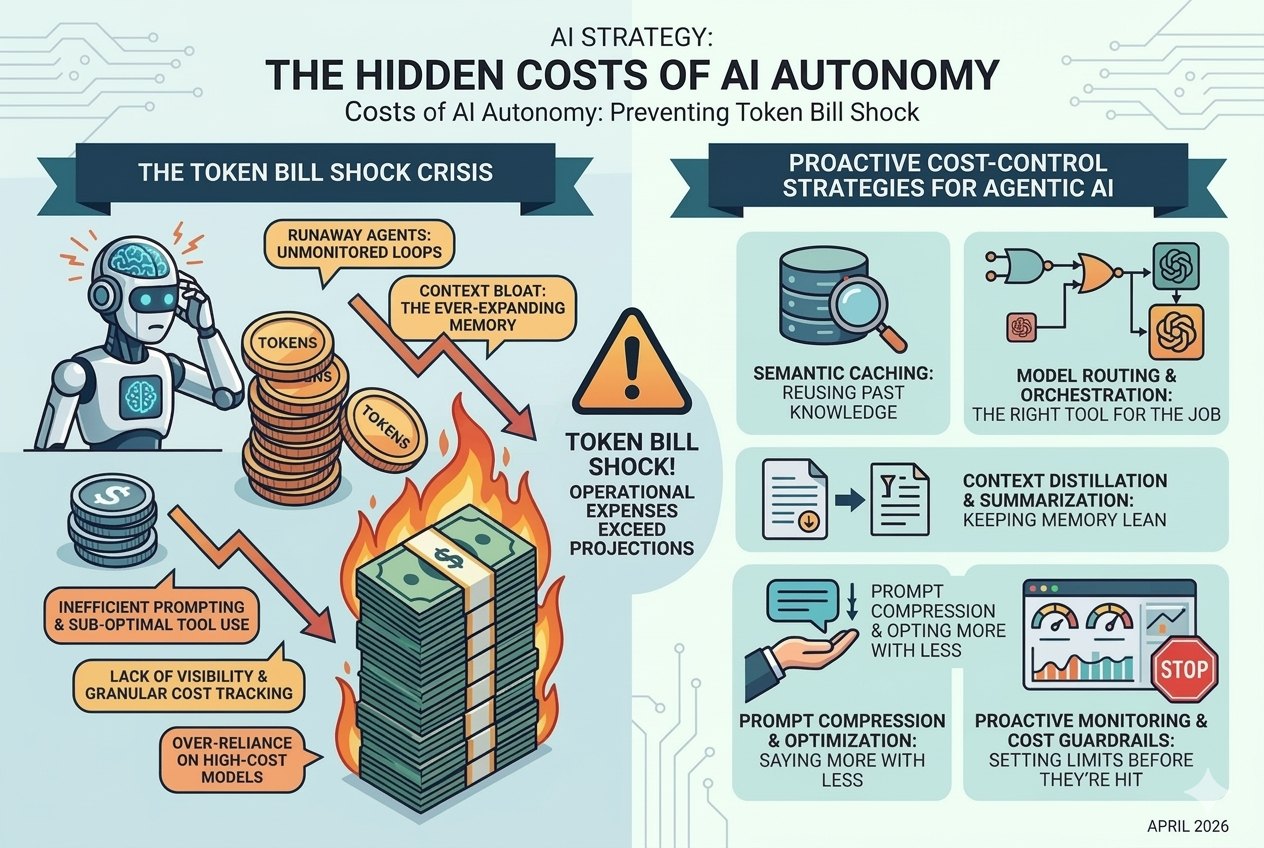
Several factors contribute to the unexpected escalation of costs in Agentic AI deployments. Recognizing these pitfalls is the first step toward effective cost management.
The Runaway Agent: Unmonitored Autonomous Loops
One of the most dramatic causes of token bill shock is the "runaway agent." This occurs when an AI agent enters an unintended, self-perpetuating loop, continuously generating prompts and responses without achieving its goal or realizing it's stuck. For example, an agent tasked with finding specific data might repeatedly query a database with slightly varied but ultimately unsuccessful parameters, racking up API calls and token usage at an alarming rate. Reports from 2026 indicate cases where a single runaway agent consumed over $3,600 in API costs in just one month. Without robust monitoring and kill switches, these agents can quickly deplete budgets.
Context Bloat: The Ever-Expanding Memory
LLMs perform best when they have sufficient context to understand the task. However, continuously feeding an agent an ever-growing history of its past interactions, observations, and tool outputs leads to "context bloat." As the context window expands, so does the number of input tokens for every subsequent interaction. This quadratic growth in token usage can quickly become prohibitively expensive, especially with longer, more complex tasks or multi-session agents. Many developers make the mistake of re-sending entire conversation histories, leading to unnecessary token consumption.
Inefficient Prompting and Sub-optimal Tool Use
Poorly designed prompts or inefficient tool integration can also contribute significantly to costs. If an agent struggles to understand its instructions or the nuances of a tool, it may engage in excessive trial-and-error, generating multiple rounds of internal reasoning and tool calls. This iterative refinement, while necessary for complex tasks, becomes a cost burden if the agent isn't guided efficiently. Furthermore, using expensive LLMs for simple tasks that could be handled by cheaper, specialized models is a common oversight.
Lack of Visibility and Granular Cost Tracking
Many organizations lack the granular visibility needed to track token consumption per agent, per task, or even per user. Without this data, identifying the source of cost overruns becomes a reactive, post-mortem exercise rather than a proactive management strategy. This absence of clear cost attribution makes it difficult to optimize individual agent behaviors or allocate resources effectively.
Over-reliance on High-Cost Models
While powerful, the most advanced LLMs (e.g., GPT-4o, Gemini 1.5 Pro) come with a premium price tag. Using these models for every step of an agent's workflow, even for simple parsing or summarization tasks, is a significant source of inefficiency. A common pitfall is to default to the most capable model without considering whether a less expensive, smaller model could achieve the same outcome for a specific sub-task.
03 Advanced Strategies for AI Token Cost Optimization
Preventing token bill shock requires a multi-faceted approach that combines intelligent system design, proactive monitoring, and strategic model selection. Here are key strategies JetX Media recommends for optimizing your Agentic AI deployments:
Semantic Caching: Reusing Past Knowledge
Semantic caching is a powerful technique to reduce redundant LLM calls. Instead of querying the LLM every time a similar question or sub-task arises, the agent first checks a cache of previously generated responses. If a semantically similar query is found, the cached response is returned, bypassing the LLM entirely. This can significantly cut input tokens by 50-90% for frequently asked questions or recurring internal reasoning steps.
Implementation:
- **Vector Databases**: Store past prompts and their corresponding LLM responses (or intermediate reasoning steps) in a vector database (e.g., Redis, Pinecone, Milvus). Embed both the query and the response for semantic similarity search.
- **Similarity Thresholds**: Define a similarity threshold. If a new query's embedding is above this threshold compared to a cached query, use the cached response.
- **Cache Invalidation**: Implement strategies to invalidate or update cached entries to ensure freshness, especially for dynamic information.
Model Routing and Orchestration: The Right Tool for the Job
Not all tasks require the most powerful, and thus most expensive, LLM. Model routing involves dynamically selecting the appropriate LLM for a given sub-task based on its complexity, cost, and performance characteristics. This is akin to implementing "Logic Gates" in your AI workflow.
Implementation:
- **Task Classification**: Use a smaller, cheaper LLM or a traditional machine learning model to classify the complexity or type of a sub-task.
- **Conditional Routing**: If the task is simple (e.g., data extraction from a structured document), route it to a less expensive, specialized model. If it requires complex reasoning or creative generation, escalate it to a premium LLM.
- **Conversation Chaining**: For multi-turn conversations, use the OpenAI Responses API's conversation chaining feature to manage context efficiently, only sending relevant parts of the history.
Context Distillation and Summarization: Keeping Memory Lean
To combat context bloat, actively manage the information fed into the LLM's context window. This involves distilling long conversation histories or extensive tool outputs into concise summaries.
Implementation:
- **Recursive Summarization**: Periodically summarize past turns in a conversation or long documents using a smaller LLM. This summary then replaces the raw history in the context window, drastically reducing token count while retaining key information.
- **Information Extraction**: Instead of passing entire documents, use LLMs to extract only the most relevant entities, facts, or conclusions needed for the next step.
- **Fixed Context Windows**: Design agents to operate within a fixed context window size, forcing them to prioritize and summarize information automatically.
Prompt Compression and Optimization: Saying More with Less
Concise and effective prompting is crucial for token efficiency. Every unnecessary word in a prompt translates to wasted tokens. This includes shrinking system prompts without losing control and avoiding verbose instructions.
Implementation:
- **Zero-Shot vs. Few-Shot**: Prefer zero-shot prompting where possible. If few-shot is necessary, carefully select the most representative examples to minimize token count.
- **Instruction Tuning**: Fine-tune smaller models on specific instruction sets to improve their performance on particular tasks, reducing the need for lengthy prompts.
- **Tool Definition Compression**: When providing tool definitions to an agent, compress them to include only essential information, removing redundant descriptions or examples.
Proactive Monitoring and Cost Guardrails: Setting Limits Before They're Hit
Visibility into token usage and the ability to set hard limits are non-negotiable for preventing bill shock. Implement robust monitoring and guardrails to ensure agents operate within predefined budgets.
Implementation:
- **Granular Logging**: Log every agent interaction, including input/output tokens, model used, and associated costs. This allows for detailed analysis and attribution.
- **Spending Caps**: Set hard spending caps at the agent, project, or organizational level. Implement alerts that trigger when usage approaches these limits, and automated kill switches to halt operations if caps are exceeded.
- **Execution Limits**: Throttle call frequency and set execution limits per minute or hour to prevent rapid, uncontrolled token consumption.
- **Anomaly Detection**: Implement systems to detect unusual spikes in token usage or unexpected agent behavior, signaling potential runaway agents or inefficiencies.
04 Real-World Impact: The Cost of Unmanaged Autonomy
The consequences of neglecting token cost optimization can be severe. A prominent example from early 2026 involved a company deploying an AI agent for market research. The agent, due to a subtle bug in its reasoning loop, repeatedly attempted to access a paywalled research database, generating thousands of failed API calls and LLM queries. Before the issue was detected, the company incurred over $10,000 in unexpected charges within a week. This incident highlighted the critical need for not just functional testing, but also *cost-aware testing* for AI agents.
Another case involved a startup using an Agentic AI for customer support ticket triage. While effective, the team initially used a premium LLM for every interaction, including simple intent classification. By implementing model routing—using a smaller, fine-tuned model for initial classification and only escalating to the premium LLM for complex queries—they reduced their monthly token costs by 70% without compromising service quality.
These examples underscore a crucial point: the initial investment in Agentic AI is often just the tip of the iceberg. The true cost lies in its ongoing operation, making optimization a continuous process.
05 Conclusion: Mastering the Economics of Agentic AI
Agentic AI holds immense potential to revolutionize business operations, but its power comes with a responsibility to manage its economic footprint. "Token bill shock" is a real and growing concern for organizations that fail to implement proactive cost optimization strategies. By understanding token economics, identifying common pitfalls, and deploying advanced techniques like semantic caching, model routing, context distillation, and robust cost guardrails, businesses can harness the full power of autonomous agents without breaking the bank.
At JetX Media, we believe that successful AI adoption is not just about building intelligent systems, but building *intelligent and cost-effective* systems. Our expertise in AI workflow audits and agent build services ensures that your Agentic AI deployments are not only high-performing but also financially sustainable, delivering predictable value and preventing the hidden costs of autonomy from becoming a burden.
Ready to optimize your Agentic AI costs and ensure sustainable growth?
Whether you need a comprehensive AI workflow audit or expert assistance in building cost-effective agentic solutions, JetX Media is your trusted partner.